

An Agentic Engineering Workflow
An approach to software engineering that works for me, for now.

Early last year, I said to a friend, “If AI only ever gives me the world’s greatest autocomplete, that’s good enough for me.” At this point, describing the whiplash every software engineer feels as we reinvent our profession is a tired trope, but that statement from a year ago feels pretty quaint now. Fast forward to today. Like most software engineers I talk to, being hands-on doesn’t translate to writing very much code.
The promise of agentic coding is that it allows engineers (and non-engineers) to focus on the business, product, and technical problems without needing to fuss over the boring parts, like standard boilerplate. The profession of software engineering has romanticized writing code and made it a defining feature of the work because, well, it’s pretty fun. In truth, code has simply been, for the last several decades, the best layer of abstraction to get computers to do exactly what you want them to do. It is hard not to think of the old quote attributed to David Wheeler:
“All problems in computer science can be solved by another level of indirection”
— David Wheeler
It is not a stretch to argue — and I am not the first to do so — that agentic coding is the next evolution of indirection and abstraction for getting computers to do exactly what you want them to do. LLMs allow engineers to take an imprecise yet familiar technology, natural language, and use it for work that demand precision.
While it is difficult to predict what a typical engineering workflow will look like a year from now — last month’s methods already seem painfully out of date — but I have settled on something I like for now.
How I work today
Most days, I switch between three modes:
Task definition
Agent monitoring
Testing
Work usually a cycles through those modes, in that order. Every now and then, despite everything, there is a fourth mode:
Writing code
Task Management
Task definition is by far the most important phase of work right now. It is, in effect, the new code I write to accomplish a task. I use Linear for Fugue, and most clients I have consulted with in recent years use it or a close relative too. Depending on the problem that needs solving, I will either define a Linear project or issue. How I choose between the two depends on the complexity of the problem and how easily I can describe it. In this sense, precision of language becomes the bottleneck, and I have developed a riff on classic Eisenhower Matrix.
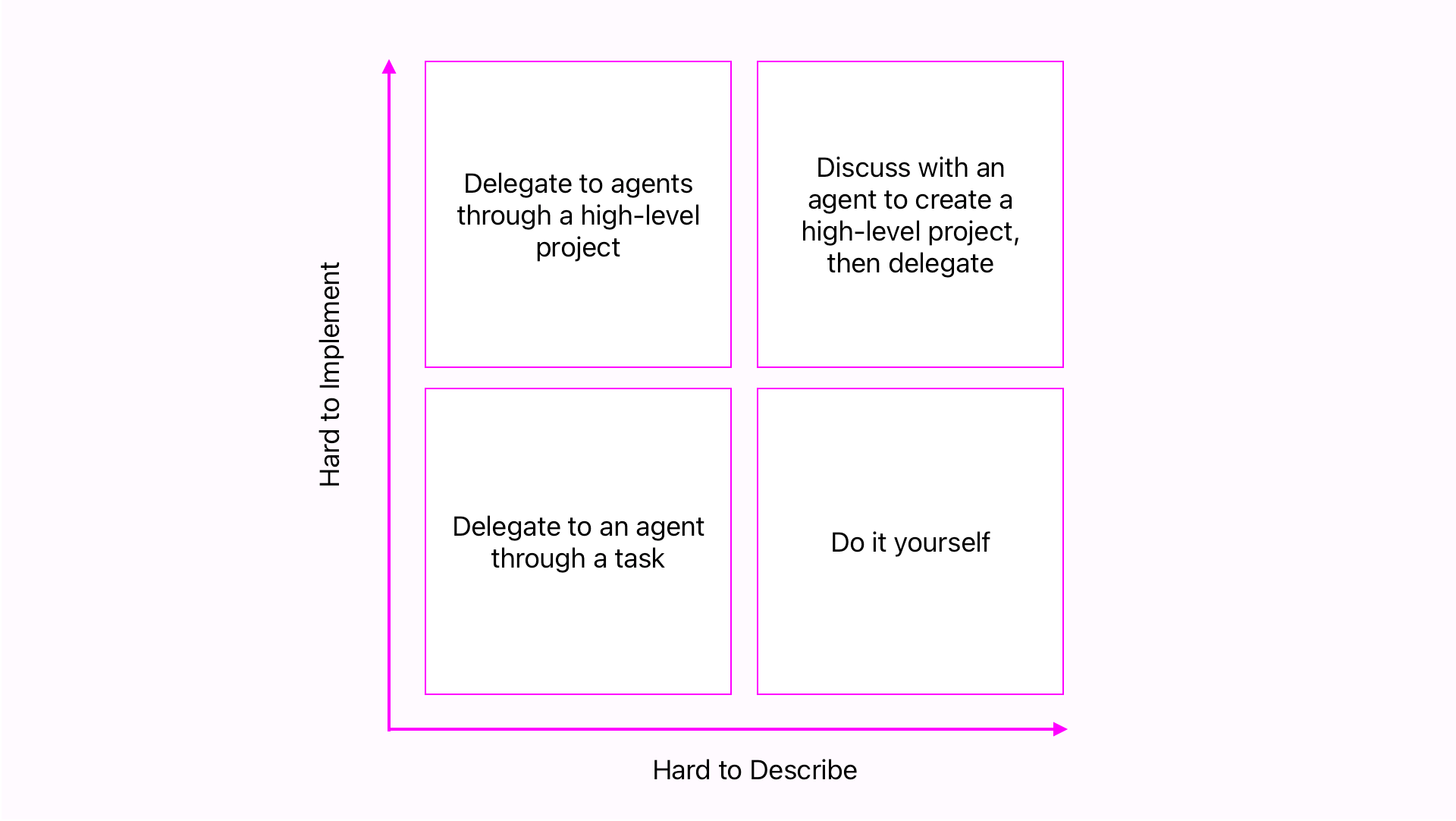
Many, possibly most, tasks are pretty easy to describe and easy to implement. This is true of most bugs, for example — where the challenge is often figuring out what the ultimately simple implementation will be — but it is also true of many infrastructure tasks and feature development work. Here, “easiness” is more about how straightforward a solution is than how many lines of code will be required to complete it. Something can be painstaking, time consuming, and tedious but still be easy. For these, it is usually enough to define a single task for an agent to work on.
For large features, a well-defined project is the most important piece. Here, a “medium” level of detail is usually enough: Describe the problem at a high level, suggest likely corners of the codebase to modify, and outline the architecture of new components. This isn’t much of a departure from a non-agentic workflow, really. Meetings with other member of the (human) team may still be needed. Heated, and hopefully fun, debates may still simmer for days. At the end of the process, though, a high quality project description is the authoritative resource agents will use to decompose the problem into specific tasks.
Sometimes, all I have is a short brief on what to build. It may be general problem statement provided by a client, or I may not have a clear picture in my own head of what I want to build. When that happens, and it does not make sense to work out the details with the rest of the team, I simply use that brief as a starting point in the project description. To make it clear there is work to do before handing it off for implementation, I set the status to something like “Planned.”
Prompting and Monitoring
I am an obnoxious vim devotee. I use it because I greatly value control over my tools, am willing to invest time into tailoring them to my needs, and prefer using open source software when I can. In that same vein, my preferred coding agent — as opposed to model — is OpenCode. It is endlessly configurable, and being open source means that, when you want to understand why something works the way it does, you can go read the implementation. For a few blissful weeks, I used it in partnership with my Claude subscription. That is, until Anthropic blocked third part integrations with Pro and Max accounts. While I was a little distraught with being forced use Claude Code a significant amount of the time instead of my tool of choice, I get that they are trying to build a product. Although I can still use Anthropic model in OpenCode to great effect, the larger context window that comes with using them directly in Claude Code as well as its deep integrations with other tools are incredibly powerful. The dissonance has a beneficial side effect, too, in that I think about what agent is the right choice for the job at hand. It is often more cost-effective to use OpenCode, reserving the power of Claude for when you really need it.
Regardless, the approach to using both is roughly the same. For me, the key ingredient is the MCP integration with Linear. Once an issue or project is well-defined the initial prompt for a session is simply:
Please work on DEV-123
or
Please work on the next issue in the "My Project" project
[Yes, I always say please. I think it improves the quality of the output. Someday, I will test that more formally.]
No matter how simple a task is, I always start in plan mode. Otherwise, the models are too confident and too prone to making hasty choices. A build-mode agent is incentivized to complete the task as quickly as possible, usually without asking questions. A plan-mode agent investigates and asks for needed clarity. This makes all the difference.
Often, the plan-mode phase turns into a conversation. Like a human developer, the agent often discovers flawed assumptions made when defining the tasks. Sometimes, I read a plan that faithfully follows the task as I defined it and see the faulty assumptions myself. Occasionally, everything looks good, and I kick it over to build mode without changes.
Once an agent is building, it is tempting to walk away. Especially for more complex tasks, it pays to key an eye on the agent and subagents’ internal dialogs as they stream down the chat window. Build agents are prone to going down rabbit holes. They may see one corner of the codebase and never explore the rest. Long-term memory is still a challenge here. An agent starting a new context window after compacting the previous one may not retain all the knowledge it had at its fingertips just a few minutes earlier. It may even go down the same rabbit hole repeatedly as the context window refreshes.
Since I own the output, it is my responsibility to keep agents focused and on-track.
From Projects to Issues
If a well-defined Linear issue is like programming at a higher level of abstraction that writing code, a project is one level of abstraction higher than that. The initial prompt is still simple:
Please help me define all issues for the "My Project" project
If the project is sufficiently detailed, this is easy. Although there will likely be a discussion about how issues are dependent on or block each other, it mostly remains an exercise in moving from a less precise definition of work to be done to a more precise set of tasks. Now that Claude supports agent teams, I sometimes ask whether using that feature is appropriate for the project of if the standard subagent structure is sufficient. This inevitably leads to a analysis of cost vs speed.
If a project is still a little nebulous, it is import to recognize it is too early to break it down into specifics. Instead, it is time for a discussion:
Please help me flesh out the definition of the "My Project" project
For me, this is often the most fun way to define a project, and there a few ways to approach the discussion. Depending the kind of thinking you want to engage with, custom agents are useful here. You can opt to invoke the agent expressly, or you can let the plan mode agent decide when to invoke one of your custom subagents. I leand toward the latter approach when don't know exactly where the conversation needs to go. And that is most of the time when I am in this phase.
This level of project definition is much closer to vibe coding, but there is a key difference. I do not expect the conversation to result in production-ready code. Depending on how vague the idea is, it may be worth creating a demo in a side conversation, but the output of this type of conversation is a more detailed project specification.
With the spec in hand, I can proceed to the previously discussed, next level of precision of turning the project into individual tasks.
Testing
When testing, I approach validating the changes as if they were my own. However, there are additional considerations:
Because agents lack the long-term memory and context about my product that I have, their changes often benefit from a little extra time spent testing. Claude can verify its own UI changes in the browser, but it might not know that a choice of color was not consistent with the rest of the product. That’s an aesthetic choice that may not be obvious just from reading the code.
Because I may not have reviewed every line of code the agent wrote at this point, I am actually a better suited for testing. I am a little closer to being a formal QA tester, with full context of the problem being solved but without the bias of knowing the happy path through it.
For fugue, it is especially important to test changes to synthesis modules because the coding agents have repeatedly shown that they aren’t great at hearing music. They can verify that audio samples are being produced or that significant clipping occurs on an audio stream, but they are terrible at knowing whether an ADSR envelope sounds good.
To be fair, I have met plenty of human engineers who struggle with these thing. And it is not what coding agents were trained for.
The Pattern
This article has emphasized abstraction and indirection repeatedly, with multiple layers of it corresponding to one’s own understanding of a problem to solve. Always, the goal is to achieve level of precision sufficient enough to get a computer to do what we want it to do. Assembly language is an easier abstraction to work with than ones and zeros, just as a low-level programming is easier than assembly, an interpreted language than a low-level one, an so on. A key trade-off has always between how precise the level of control is vs how quickly and easily the work can be completed.
Not Allowed, Yet
As powerful tools enhance speed and ease of work, the relinquishing of control requires trust. For me, there are a number of layers of control I am not ready to give up. I expect at least some of these to change over time, but for now, I do not let AI agents take some key actions:
Claim authorship of commits. I am open about what tools I use, but I am accountable for the result. At the very least, I want the paper trail to be unambiguous.
Merge pull requests. I review and understand all code that will have my name attached to it.
Interact with a production database. When possible, I run a complete environment locally. This can create additional challenges when local data is not a perfect reflection of production, but such a level of access is the ultimate trust issue. At the very least, I must thoroughly understand any query that an agent writes on my behalf.
And Sometimes I Write Code
In the decision matrix above, there is one clear condition when it is best to code something yourself: if it is hard to explain and easy to implement. Some bugs fall into this category, as do a few smaller features. Or, it might be faster to go change those wrong colors discovered during testing than to type all the words required to get an agent to do it.
The most common case, however, is when an agent gets stuck or reaches the limits of its ability in some way. Recently, I could hear an issue with sample rate in Fugue. It is and easy thing to identify once you are used to it: audio will sound just a little bit higher or lower in pitch than it should. According to my agent, there were no errors, and this was correct. No matter how much I described what I was experiencing, it simply could not understand because it could not hear the music sounding wrong. Ultimately, I needed to change one line of code, and the lesson was to pay close enough attention to see when the agent is no longer the right tool for the job. Every now and then, the right tool is me.
Of course, there is another case when I write code: when I want to. As with creating music, struggling through the details brings brings meaning and is important for understanding something. As colleague once said, “If I can’t program it, I don’t fully know it.”
Also, writing code can be pretty fun, especially when you have the world’s greatest autocomplete to help you out.
Excellent article and glad you are writing :) The simple decision matrix is a great visual!